
NiFi ExecuteStreamCommand로 Python 스크립트를 실행하여 웹크롤링 데이터를 가져오는 방법
1. 시작 전 설명
ExecuteStreamCommand?
ExecuteStreamCommand 프로세서는 외부 명령과 스크립트를 NiFi 데이터 흐름에 통합하는 유연한 방법을 제공합니다. ExecuteStreamCommand는 들어오는 FlowFile의 콘텐츠를 파이핑 작동 방식과 유사하게 실행하는 명령에 전달할 수 있습니다.
ExecuteStreamCommand
Description The ExecuteStreamCommand processor provides a flexible way to integrate external commands and scripts into NiFi data flows. ExecuteStreamCommand can pass the incoming FlowFile's content to the command that it executes similarly how piping works
nifi.apache.org
NiFi에서는 다른 언어로 데이터의 흐름을 더 유연하게 할 수도 있는 것 같습니다.
대표적으로 ExecuteScript, 그리고 Java로 CustomProcessor 만드는 방법이 있지만 해당 방법은 스크립트를 실행시키고 출력 물을 가져오는 프로세서입니다.
ExecuteStreamCommand는 출력 관계가 총 3개 있으며 종류는 아래와 같습니다.
- nonzero status
- 반환된 상태 코드가 0이 아닌 경우 명령 출력에서 생성된 흐름 파일의 대상 경로입니다. 이 관계로 라우팅 된 모든 흐름 파일에 불이익이 적용됩니다.
- original
- 원본 FlowFile이 라우팅 됩니다. 스크립트 실행 결과를 자세히 설명하는 새 속성이 있습니다.
- output stream
- 반환된 상태 코드가 0인 경우 명령 출력에서 생성된 흐름 파일의 대상 경로입니다.
물론 PythonScript뿐만 아니라 sh파일 등등 출력이 있는 스크립트 모두 가능합니다.
ExecuteStreamCommand Properties
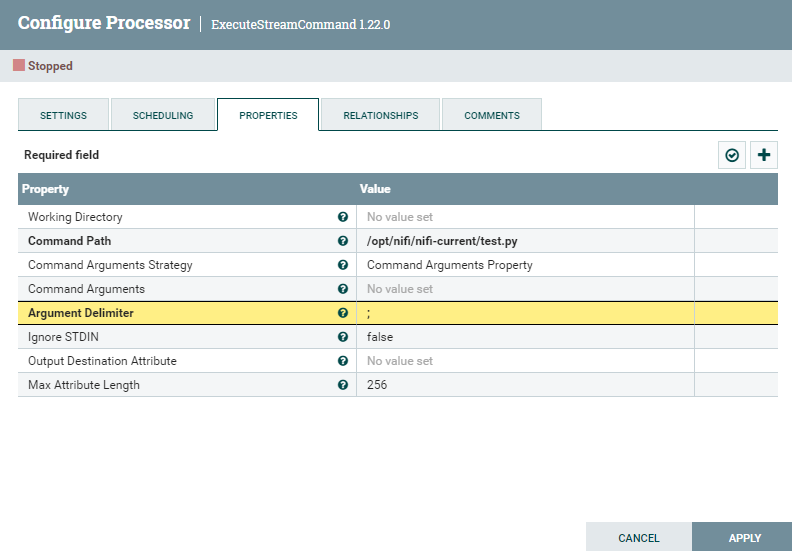
| Working Directory | 작업 디렉토리 지정 |
| Command Path | 해당 작업디렉토리에서 실행할 스크립트 이름 작성 |
| Command Arguments Strategy | 명령에 제공할 인수를 구성하기 위한 전략입니다.(번역) |
| Command Arguments | 넣어줄 인수(여러개일 경우 `;`로 구분) |
| Argument Delimiter | 인수 구분 기호 (기본 `;`) 기호를 바꾸면 Command Arguments의 구분 기호를 바꿔 줘야함 |
| Ignore STDIN | true인 경우 들어오는 흐름 파일의 내용이 실행 명령으로 전달되지 않습니다. (번역) |
| Output Destination Attribute | 설정하면 스트림 명령의 출력이 별도의 FlowFile 대신 원래 FlowFile의 속성에 저장됩니다. 더 이상 '출력 스트림' 또는 '0이 아닌 상태'에 대한 관계가 없습니다. 이 속성의 값은 출력 속성의 키가 됩니다. (번역) |
| Max Attribute Length | 스트림 명령의 출력을 속성으로 라우팅하는 경우 속성 값에 입력되는 문자 수는 최대 이 양입니다. 이는 속성이 메모리에 저장되고 속성이 크면 메모리 부족 문제가 빠르게 발생하기 때문에 중요합니다. 출력이 이 값보다 길어지면 크기에 맞게 잘립니다. 가능하면 더 작게 만드는 것을 고려하십시오. (번역) |
웹 크롤링 Web crawling(Web scraping)?
웹 크롤링은 인터넷상의 웹 페이지를 자동으로 탐색하고, 필요한 데이터를 수집하는 프로세스를 말합니다. 웹 크롤러 또는 스파이더라고도 불리는 소프트웨어 프로그램이 사용됩니다.
일반적으로 웹 크롤링은 다음과 같은 단계로 이루어집니다
- 웹 크롤러는 시작점으로 설정된 웹 페이지를 방문합니다. 이 페이지는 일반적으로 검색 엔진의 결과 페이지, 사이트의 메인 페이지 등이 될 수 있습니다.
- 웹 크롤러는 방문한 페이지의 HTML 코드를 분석하고, 하이퍼링크를 추출합니다. 하이퍼링크는 다른 웹 페이지로 이동할 수 있는 링크를 의미합니다.
- 추출한 하이퍼링크를 크롤링 대상 목록에 추가하고, 다음 페이지로 이동합니다. 이 과정을 재귀적으로 반복하면서 여러 웹 페이지를 탐색합니다.
- 방문한 각 웹 페이지에서 필요한 데이터를 수집합니다. 데이터 수집은 HTML 구조를 분석하거나 정규표현식, XPath 등의 방법을 사용할 수 있습니다. 데이터는 일반적으로 텍스트, 이미지, 링크 등 다양한 형식일 수 있습니다.
- 수집한 데이터를 원하는 형식으로 가공 또는 저장합니다. 이 데이터는 후속 분석, 데이터베이스에 저장, 웹 사이트에 표시 등 다양한 용도로 활용될 수 있습니다.
웹 크롤링은 다양한 목적으로 사용될 수 있습니다. 예를 들어, 검색 엔진은 웹 크롤링을 통해 웹 페이지를 인덱싱하여 사용자의 검색에 응답합니다. 또한, 가격 비교 사이트는 여러 온라인 상점의 제품 정보를 수집하여 비교 결과를 제공합니다. 뉴스 사이트나 소셜 미디어 플랫폼은 웹 크롤링을 통해 실시간으로 최신 정보를 수집하여 제공할 수 있습니다.
웹 크롤링은 법적, 윤리적인 제약사항을 고려해야 합니다. 일부 웹 사이트는 크롤링을 제한하거나 허용한도를 설정할 수 있습니다. 따라서, 웹 크롤링을 수행하기 전에 해당 웹 사이트의 이용 약관을 확인하고, 크롤링에 대한 규칙을 준수해야 합니다.
웹 크롤링은 selenium을 사용합니다.
2. 파이썬 파일 작성 | 부제 - cli 환경의 서버에서 드라이버 불러오기 없이 웹크롤링하기
아래 사이트에서 제목을 출력해 보는 코딩을 해볼 겁니다.
“5000만원 목돈 왜 청년만”…40대도 청년도약계좌 안되겠니 - 매일경제
중소기업에 다니는 40대 A씨는 청년도약계좌 소식을 들을 때마다 짜증이 몰려온다. 가정을 꾸린 후 돈 들어갈 곳은 더 많아지고 노후 준비 또한 쉽지 않은데, 유독 청년층에만 각종 혜택을 주는
www.mk.co.kr
그전에 서버에 Python과 pip , selenium , webdriver-manager를 설치하겠습니다.
제 환경은 아래와 같습니다.
설치 환경
- Synology DS 218+ 셀러론 , 10GB RAM
- Docker NiFi 컨테이너 내부(Ubuntu) (`docker exec -itu 0 nifi bash` 로 root로 접속함.)
아래 코드를 순서대로 입력합니다.(해당 코드는 root 계정 기준입니다.)
Python , pip , webdriver-manager , selenium , Chrome 설치
# Python 및 pip , webdriver-manager , selenium 설치
apt update
apt install vim
apt install python3
apt install python3-pip
pip3 install webdriver-manager
pip3 install selenium
# Chrome 설치
wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -
sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
apt update
apt install google-chrome-stable
google-chrome --version #버전이 출력되면 성공그다음 Python의 설치 경로를 알아봅니다.
python3
import sys
sys.executable`sys.executable` 명령어를 입력 후 출력되는 내용을 복사해 놓거나 기억해 둡니다.
Python Script 작성
간단하게 vi 에디터로 test.py 파일을 작성해 보겠습니다.
vi test.py방금 출력된 내용을 PythonScript 최상단에 아래와 같이 입력해 줍니다.
아래 구문을 꼭 최상단에 넣어줘야 합니다. 그렇지 않으면 NiFi에서 실행시키지 못합니다.
써 줘야 하는 이유는 아래와 같습니다.
- test.py 파일을 실행시키기 위해서는 `python3 test.py` 커멘트로 실행시켜줘야 함
- 아래 내용을 최상단에 입력하게 되면 아래와 명령어로 바로 실행이 가능하다.
- `./test.py`
#!<붙여놓기>
#ex
#!/usr/bin/python3
총 크롤링 하는 구문은 아래와 같습니다.
#!/usr/bin/python3
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--disable-extensions') #실험실 기능 끄기
chrome_options.add_argument("--disable-plugins-discovery") #플러그인 검색 비활성화
chrome_options.add_argument('--headless') #헤드리스모드
chrome_options.add_argument('--no-sandbox') #샌드박스 비활성화
chrome_options.add_argument("--single-process") #단일 프로세스로 실행
chrome_options.add_argument("--disable-dev-shm-usage") #공유 메모리 사용 안함
chrome_options.add_argument("app-version=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36")
#user-agent설정
chrome_options.add_experimental_option("detach", True) #종료 안함
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options) #드라이버 설치
driver.delete_all_cookies() #쿠키 제거
driver.get('https://www.mk.co.kr/news/economy/10766297')
testEX = driver.find_element(By.XPATH,'//*[@id="container"]/section/div[2]/section/div/div/div/h2').text
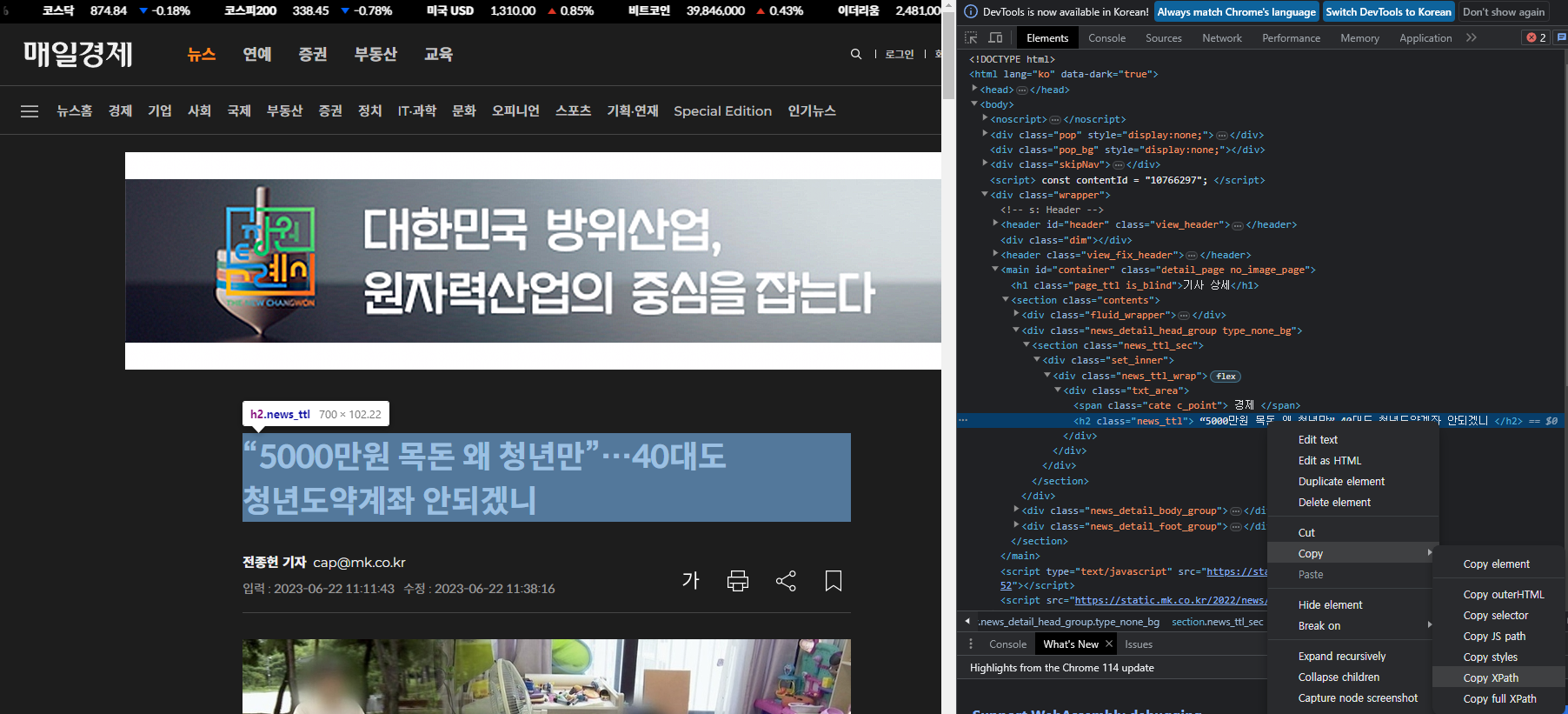
print(testEX)`'//*[@id="container"]/section/div[2]/section/div/div/div/h2'` 는 사이트에서 개발자도구를 연 다음 `Elements` 탭에서 표시되는 영역을 따라 열어주면서 XPach를 추출합니다.
일단 터미널에서 해당 코드를 실행시켜 봅니다.
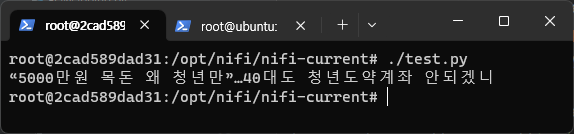
정상적으로 추출되는 모습을 확인할 수 있습니다.
최소 실행 시 드라이버를 다운로드합니다.
해당 구문을 그냥 복붙 하시면 따로 드라이버 잡아주는 작업은 필요 없습니다.
잘 동작하는 것을 확인했으니 이제 권한 부여를 해줍니다.
chmod 777 test.py그다음 test.py 파일의 절대 경로를 아래 명령어로 실행 후 기억해놉니다.(test.py가 있는 디렉터리에서 실행)
pwd
#출력
/opt/nifi/nifi-current저의 test.py 파일은 `/opt/nifi/nifi-current` 디렉토리에 있는 것을 확인할 수 있습니다. 해당 값을 복사해 둡니다.
3. ExecuteStreamCommand 사용하기
이제 NiFi로 돌아와 아래 사진과 같이 Properties를 작성합니다.
그리고 아래와 같이 flow를 작성해 줍니다.
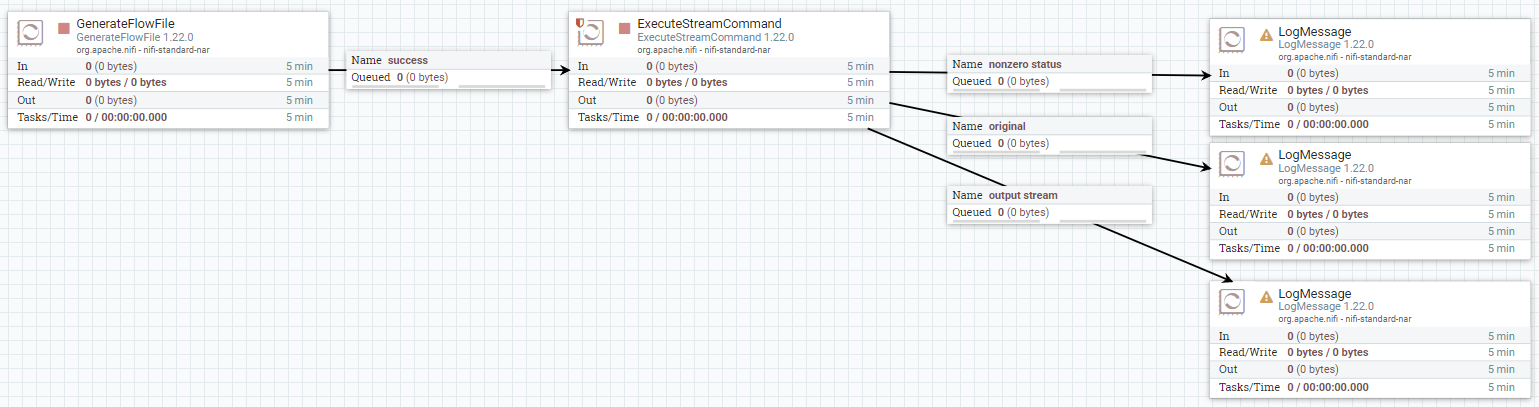
GenerateFlowFile 프로세서에는 임의의 값을 넣어줍니다.
이제 GenerateFlowFile, ExecuteStreamCommand를 활성화해줍니다. (LogMessage는 실행 안 해도 무관)
그럼 잠시 후 아래와 같이 Queue에 데이터가 쌓인 것을 확인할 수 있습니다.(서버의 성능, 인터넷 속도에 따라 대기 시간차이가 발생합니다.)
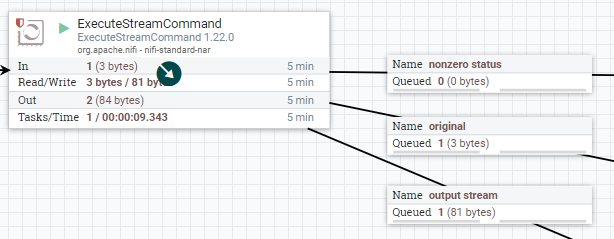
여기서 봐야 할 것은 `output stream 큐`입니다.
`output stream 큐` 를 우클릭하고 `List Queue`를 클릭하여 눈모양 아이콘을 클릭해 봅니다.

이렇게 FlowFile Content에 크롤링된 데이터가 있는 모습을 알 수 있습니다.
이렇게 저희는 이 포스트를 통해 아래와 같은 사실을 알 수 있게 되었습니다.
- ExecuteStreamCommand
- 서버에서 Chrome 설치
- WebDriver를 추가하지 않고 WebDriver 사용하기
- selenium
- chrome_options.add_argument
- XPath 추출 방법
크롬 설치 부분은 아래 링크를 참고하였습니다. 감사합니다.
[Ubuntu] Ubuntu 서버에 Selenium 설치하고 사용하기
Mac에서 Selenium을 활용하여 열심히 크롤링 코드를 작성하여 제대로 동작하는지 확인한 후 호기롭게 Ubuntu 서버에 그대로 파일을 옮긴 뒤 selenium 라이브러리를 설치하고 Linux용 chromedriver를 다운받
somjang.tistory.com
'NiFi' 카테고리의 다른 글
| [탬플릿] NiFi 로그추적기 (0) | 2024.08.23 |
|---|---|
| NiFi TailFile (1) | 2024.01.17 |
| NiFi Custom Processor 만들기 (0) | 2023.05.31 |
| Remote Process Group 사용법 (0) | 2023.05.24 |
| NiFi parameter contexts 추출 및 불러오는 방법(백업/복원 방법) (0) | 2023.05.23 |
NiFi ExecuteStreamCommand로 Python 스크립트를 실행하여 웹크롤링 데이터를 가져오는 방법
1. 시작 전 설명
ExecuteStreamCommand?
ExecuteStreamCommand 프로세서는 외부 명령과 스크립트를 NiFi 데이터 흐름에 통합하는 유연한 방법을 제공합니다. ExecuteStreamCommand는 들어오는 FlowFile의 콘텐츠를 파이핑 작동 방식과 유사하게 실행하는 명령에 전달할 수 있습니다.
ExecuteStreamCommand
Description The ExecuteStreamCommand processor provides a flexible way to integrate external commands and scripts into NiFi data flows. ExecuteStreamCommand can pass the incoming FlowFile's content to the command that it executes similarly how piping works
nifi.apache.org
NiFi에서는 다른 언어로 데이터의 흐름을 더 유연하게 할 수도 있는 것 같습니다.
대표적으로 ExecuteScript, 그리고 Java로 CustomProcessor 만드는 방법이 있지만 해당 방법은 스크립트를 실행시키고 출력 물을 가져오는 프로세서입니다.
ExecuteStreamCommand는 출력 관계가 총 3개 있으며 종류는 아래와 같습니다.
- nonzero status
- 반환된 상태 코드가 0이 아닌 경우 명령 출력에서 생성된 흐름 파일의 대상 경로입니다. 이 관계로 라우팅 된 모든 흐름 파일에 불이익이 적용됩니다.
- original
- 원본 FlowFile이 라우팅 됩니다. 스크립트 실행 결과를 자세히 설명하는 새 속성이 있습니다.
- output stream
- 반환된 상태 코드가 0인 경우 명령 출력에서 생성된 흐름 파일의 대상 경로입니다.
물론 PythonScript뿐만 아니라 sh파일 등등 출력이 있는 스크립트 모두 가능합니다.
ExecuteStreamCommand Properties
| Working Directory | 작업 디렉토리 지정 |
| Command Path | 해당 작업디렉토리에서 실행할 스크립트 이름 작성 |
| Command Arguments Strategy | 명령에 제공할 인수를 구성하기 위한 전략입니다.(번역) |
| Command Arguments | 넣어줄 인수(여러개일 경우 `;`로 구분) |
| Argument Delimiter | 인수 구분 기호 (기본 `;`) 기호를 바꾸면 Command Arguments의 구분 기호를 바꿔 줘야함 |
| Ignore STDIN | true인 경우 들어오는 흐름 파일의 내용이 실행 명령으로 전달되지 않습니다. (번역) |
| Output Destination Attribute | 설정하면 스트림 명령의 출력이 별도의 FlowFile 대신 원래 FlowFile의 속성에 저장됩니다. 더 이상 '출력 스트림' 또는 '0이 아닌 상태'에 대한 관계가 없습니다. 이 속성의 값은 출력 속성의 키가 됩니다. (번역) |
| Max Attribute Length | 스트림 명령의 출력을 속성으로 라우팅하는 경우 속성 값에 입력되는 문자 수는 최대 이 양입니다. 이는 속성이 메모리에 저장되고 속성이 크면 메모리 부족 문제가 빠르게 발생하기 때문에 중요합니다. 출력이 이 값보다 길어지면 크기에 맞게 잘립니다. 가능하면 더 작게 만드는 것을 고려하십시오. (번역) |
웹 크롤링 Web crawling(Web scraping)?
웹 크롤링은 인터넷상의 웹 페이지를 자동으로 탐색하고, 필요한 데이터를 수집하는 프로세스를 말합니다. 웹 크롤러 또는 스파이더라고도 불리는 소프트웨어 프로그램이 사용됩니다.
일반적으로 웹 크롤링은 다음과 같은 단계로 이루어집니다
- 웹 크롤러는 시작점으로 설정된 웹 페이지를 방문합니다. 이 페이지는 일반적으로 검색 엔진의 결과 페이지, 사이트의 메인 페이지 등이 될 수 있습니다.
- 웹 크롤러는 방문한 페이지의 HTML 코드를 분석하고, 하이퍼링크를 추출합니다. 하이퍼링크는 다른 웹 페이지로 이동할 수 있는 링크를 의미합니다.
- 추출한 하이퍼링크를 크롤링 대상 목록에 추가하고, 다음 페이지로 이동합니다. 이 과정을 재귀적으로 반복하면서 여러 웹 페이지를 탐색합니다.
- 방문한 각 웹 페이지에서 필요한 데이터를 수집합니다. 데이터 수집은 HTML 구조를 분석하거나 정규표현식, XPath 등의 방법을 사용할 수 있습니다. 데이터는 일반적으로 텍스트, 이미지, 링크 등 다양한 형식일 수 있습니다.
- 수집한 데이터를 원하는 형식으로 가공 또는 저장합니다. 이 데이터는 후속 분석, 데이터베이스에 저장, 웹 사이트에 표시 등 다양한 용도로 활용될 수 있습니다.
웹 크롤링은 다양한 목적으로 사용될 수 있습니다. 예를 들어, 검색 엔진은 웹 크롤링을 통해 웹 페이지를 인덱싱하여 사용자의 검색에 응답합니다. 또한, 가격 비교 사이트는 여러 온라인 상점의 제품 정보를 수집하여 비교 결과를 제공합니다. 뉴스 사이트나 소셜 미디어 플랫폼은 웹 크롤링을 통해 실시간으로 최신 정보를 수집하여 제공할 수 있습니다.
웹 크롤링은 법적, 윤리적인 제약사항을 고려해야 합니다. 일부 웹 사이트는 크롤링을 제한하거나 허용한도를 설정할 수 있습니다. 따라서, 웹 크롤링을 수행하기 전에 해당 웹 사이트의 이용 약관을 확인하고, 크롤링에 대한 규칙을 준수해야 합니다.
웹 크롤링은 selenium을 사용합니다.
2. 파이썬 파일 작성 | 부제 - cli 환경의 서버에서 드라이버 불러오기 없이 웹크롤링하기
아래 사이트에서 제목을 출력해 보는 코딩을 해볼 겁니다.
“5000만원 목돈 왜 청년만”…40대도 청년도약계좌 안되겠니 - 매일경제
중소기업에 다니는 40대 A씨는 청년도약계좌 소식을 들을 때마다 짜증이 몰려온다. 가정을 꾸린 후 돈 들어갈 곳은 더 많아지고 노후 준비 또한 쉽지 않은데, 유독 청년층에만 각종 혜택을 주는
www.mk.co.kr
그전에 서버에 Python과 pip , selenium , webdriver-manager를 설치하겠습니다.
제 환경은 아래와 같습니다.
설치 환경
- Synology DS 218+ 셀러론 , 10GB RAM
- Docker NiFi 컨테이너 내부(Ubuntu) (`docker exec -itu 0 nifi bash` 로 root로 접속함.)
아래 코드를 순서대로 입력합니다.(해당 코드는 root 계정 기준입니다.)
Python , pip , webdriver-manager , selenium , Chrome 설치
# Python 및 pip , webdriver-manager , selenium 설치
apt update
apt install vim
apt install python3
apt install python3-pip
pip3 install webdriver-manager
pip3 install selenium
# Chrome 설치
wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -
sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
apt update
apt install google-chrome-stable
google-chrome --version #버전이 출력되면 성공그다음 Python의 설치 경로를 알아봅니다.
python3
import sys
sys.executable`sys.executable` 명령어를 입력 후 출력되는 내용을 복사해 놓거나 기억해 둡니다.
Python Script 작성
간단하게 vi 에디터로 test.py 파일을 작성해 보겠습니다.
vi test.py방금 출력된 내용을 PythonScript 최상단에 아래와 같이 입력해 줍니다.
아래 구문을 꼭 최상단에 넣어줘야 합니다. 그렇지 않으면 NiFi에서 실행시키지 못합니다.
써 줘야 하는 이유는 아래와 같습니다.
- test.py 파일을 실행시키기 위해서는 `python3 test.py` 커멘트로 실행시켜줘야 함
- 아래 내용을 최상단에 입력하게 되면 아래와 명령어로 바로 실행이 가능하다.
- `./test.py`
#!<붙여놓기>
#ex
#!/usr/bin/python3총 크롤링 하는 구문은 아래와 같습니다.
#!/usr/bin/python3
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--disable-extensions') #실험실 기능 끄기
chrome_options.add_argument("--disable-plugins-discovery") #플러그인 검색 비활성화
chrome_options.add_argument('--headless') #헤드리스모드
chrome_options.add_argument('--no-sandbox') #샌드박스 비활성화
chrome_options.add_argument("--single-process") #단일 프로세스로 실행
chrome_options.add_argument("--disable-dev-shm-usage") #공유 메모리 사용 안함
chrome_options.add_argument("app-version=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.75 Safari/537.36")
#user-agent설정
chrome_options.add_experimental_option("detach", True) #종료 안함
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options) #드라이버 설치
driver.delete_all_cookies() #쿠키 제거
driver.get('https://www.mk.co.kr/news/economy/10766297')
testEX = driver.find_element(By.XPATH,'//*[@id="container"]/section/div[2]/section/div/div/div/h2').text
print(testEX)`'//*[@id="container"]/section/div[2]/section/div/div/div/h2'` 는 사이트에서 개발자도구를 연 다음 `Elements` 탭에서 표시되는 영역을 따라 열어주면서 XPach를 추출합니다.
일단 터미널에서 해당 코드를 실행시켜 봅니다.
정상적으로 추출되는 모습을 확인할 수 있습니다.
최소 실행 시 드라이버를 다운로드합니다.
해당 구문을 그냥 복붙 하시면 따로 드라이버 잡아주는 작업은 필요 없습니다.
잘 동작하는 것을 확인했으니 이제 권한 부여를 해줍니다.
chmod 777 test.py그다음 test.py 파일의 절대 경로를 아래 명령어로 실행 후 기억해놉니다.(test.py가 있는 디렉터리에서 실행)
pwd
#출력
/opt/nifi/nifi-current저의 test.py 파일은 `/opt/nifi/nifi-current` 디렉토리에 있는 것을 확인할 수 있습니다. 해당 값을 복사해 둡니다.
3. ExecuteStreamCommand 사용하기
이제 NiFi로 돌아와 아래 사진과 같이 Properties를 작성합니다.
그리고 아래와 같이 flow를 작성해 줍니다.
GenerateFlowFile 프로세서에는 임의의 값을 넣어줍니다.
이제 GenerateFlowFile, ExecuteStreamCommand를 활성화해줍니다. (LogMessage는 실행 안 해도 무관)
그럼 잠시 후 아래와 같이 Queue에 데이터가 쌓인 것을 확인할 수 있습니다.(서버의 성능, 인터넷 속도에 따라 대기 시간차이가 발생합니다.)
여기서 봐야 할 것은 `output stream 큐`입니다.
`output stream 큐` 를 우클릭하고 `List Queue`를 클릭하여 눈모양 아이콘을 클릭해 봅니다.
이렇게 FlowFile Content에 크롤링된 데이터가 있는 모습을 알 수 있습니다.
이렇게 저희는 이 포스트를 통해 아래와 같은 사실을 알 수 있게 되었습니다.
- ExecuteStreamCommand
- 서버에서 Chrome 설치
- WebDriver를 추가하지 않고 WebDriver 사용하기
- selenium
- chrome_options.add_argument
- XPath 추출 방법
크롬 설치 부분은 아래 링크를 참고하였습니다. 감사합니다.
[Ubuntu] Ubuntu 서버에 Selenium 설치하고 사용하기
Mac에서 Selenium을 활용하여 열심히 크롤링 코드를 작성하여 제대로 동작하는지 확인한 후 호기롭게 Ubuntu 서버에 그대로 파일을 옮긴 뒤 selenium 라이브러리를 설치하고 Linux용 chromedriver를 다운받
somjang.tistory.com
'NiFi' 카테고리의 다른 글
| [탬플릿] NiFi 로그추적기 (0) | 2024.08.23 |
|---|---|
| NiFi TailFile (1) | 2024.01.17 |
| NiFi Custom Processor 만들기 (0) | 2023.05.31 |
| Remote Process Group 사용법 (0) | 2023.05.24 |
| NiFi parameter contexts 추출 및 불러오는 방법(백업/복원 방법) (0) | 2023.05.23 |