Reference
2026.02.03 일자 기준 공식 Playbook의 vLLM은 구버전 이슈가 있어 다른 컨테이너를 사용하였다.
GitHub - eugr/spark-vllm-docker: Docker configuration for running VLLM on dual DGX Sparks
Docker configuration for running VLLM on dual DGX Sparks - eugr/spark-vllm-docker
github.com
시작
Nvidia DGX Spark 장비는 매우 높은 VRAM을 가지고 있어 llm 모델을 추론하기 정말 좋은 장비이다(성능은 썩..)
이 장비에서 로컬 llm을 사용하려면 아래 조건을 만족해야 한다
1. 다양한 모델
- 모델: Qwen2.5 Coder 7b, 14b, 32b
2. 팀단위 동시사용(1팀 = 1 장비 = 6명 이하)
3. 그럴싸한(?) 코드 퀄리티
위 조건에 만족하는 것이 Qwen2.5 Coder 또는 DeepSeek 모델에 양자화된 모델이 적합하다 판단하였으며 우선 Qwen2.5 Coder 모델을 적용하였다.
구축은 매우 간단하며 간단히 `docker-compose.yml`만 작성해 주고 `docker compose up -d`만 "딸깍" 쳐주면 켜진다.
옵션
vLLM에는 다양한 옵션이 있는데 `claude`가 요약한 내용을 아래에 정리한다.
위 Git 저장소 내용 기준으로 질문했으며, 내용이 틀릴 수도 있음.
기본 모델 설정
| 옵션 | 설명 | 기본값 | 예시 |
| model | Hugging Face 모델 경로 또는 이름 | 필수 | meta-llama/Llama-2-7b-hf |
| --tokenizer | 토크나이저 경로 (미지정시 모델과 동일) | None | --tokenizer custom_tokenizer |
| --config | Hugging Face config 경로 | None | --config custom_config |
| --revision | 모델 버전/커밋/브랜치 | None | --revision main |
| --code-revision | 모델 코드 버전 | None | --code-revision v1.0 |
| --trust-remote-code | 원격 코드 실행 허용 | False | --trust-remote-code |
| --skip-tokenizer-init | 토크나이저 초기화 건너뛰기 | False | --skip-tokenizer-init |
메모리 및 성능 설정
| 옵션 | 설명 | 기본값 | 예시 |
| --gpu-memory-utilization | GPU 메모리 사용률 (0.0-1.0) | 0.9 | --gpu-memory-utilization 0.15 |
| --max-model-len | 최대 컨텍스트 길이 (토큰) | 모델 기본값 | --max-model-len 8192 |
| --max-num-seqs | 최대 시퀀스 수 | 256 | --max-num-seqs 8 |
| --max-num-batched-tokens | 배치당 최대 토큰 수 | None | --max-num-batched-tokens 8192 |
| --block-size | 메모리 블록 크기 | 16 | --block-size 32 |
| --num-gpu-blocks-override | GPU 블록 수 강제 지정 | None | --num-gpu-blocks-override 1000 |
| --swap-space | CPU 스왑 공간 (GiB) | 4 | --swap-space 16 |
| --cpu-offload-gb | CPU 오프로드 공간 (GiB) | 0 | --cpu-offload-gb 10 |
| --seed | 랜덤 시드 | 0 | --seed 42 |
병렬 처리 설정
| 옵션 | 설명 | 기본값 | 예시 |
| --tensor-parallel-size | 텐서 병렬 크기 | 1 | --tensor-parallel-size 1 |
| --pipeline-parallel-size | 파이프라인 병렬 크기 | 1 | --pipeline-parallel-size 2 |
| --data-parallel-size | 데이터 병렬 크기 | 1 | --data-parallel-size 2 |
| --distributed-executor-backend | 분산 백엔드 | auto | --distributed-executor-backend ray |
| --max-parallel-loading-workers | 병렬 로딩 워커 수 | None | --max-parallel-loading-workers 4 |
로딩 및 포맷 설정
| 옵션 | 설명 | 기본값 | 예시 |
| --load-format | 모델 로딩 포맷 | auto | --load-format fastsafetensors |
| --download-dir | 모델 다운로드 디렉토리 | None | --download-dir /tmp/models |
| --ignore-patterns | 무시할 파일 패턴 | original/*/ | --ignore-patterns "*.bin" |
| --preemption-mode | 선점 모드 | swap | --preemption-mode recompute |
| --enable-lora | LoRA 어댑터 활성화 | False | --enable-lora |
| --lora-modules | LoRA 모듈 설정 | None | --lora-modules name=path |
양자화 설정
| 옵션 | 설명 | 기본값 | 예시 |
| --quantization | 양자화 방법 | None | --quantization awq |
| --quantization-param-path | 양자화 파라미터 경로 | None | --quantization-param-path /path |
| --enforce-eager | CUDA 그래프 비활성화 | False | --enforce-eager |
| --kv-cache-dtype | KV 캐시 데이터 타입 | auto | --kv-cache-dtype auto |
| --quantized-kv-cache | 양자화된 KV 캐시 사용 | False | --quantized-kv-cache |
서버 설정
| 옵션 | 설명 | 기본값 | 예시 |
| --host | 서버 호스트 | localhost | --host 0.0.0.0 |
| --port | 서버 포트 | 8000 | --port 8005 |
| --uds | Unix 도메인 소켓 경로 | None | --uds /tmp/vllm.sock |
| --ssl-keyfile | SSL 키 파일 | None | --ssl-keyfile key.pem |
| --ssl-certfile | SSL 인증서 파일 | None | --ssl-certfile cert.pem |
| --ssl-ca-certs | SSL CA 인증서 | None | --ssl-ca-certs ca.pem |
| --ssl-cert-reqs | SSL 인증서 요구사항 | 0 | --ssl-cert-reqs 1 |
API 및 로깅 설정
| 옵션 | 설명 | 기본값 | 예시 |
| --api-key | API 키 요구 | None | --api-key your-secret-key |
| --served-model-name | API에서 사용할 모델명 | 모델명과 동일 | --served-model-name custom-name |
| --chat-template | 채팅 템플릿 경로 | None | --chat-template template.jinja |
| --response-role | 응답 역할 | assistant | --response-role bot |
| --disable-log-stats | 통계 로깅 비활성화 | False | --disable-log-stats |
| --disable-log-requests | 요청 로깅 비활성화 | False | --disable-log-requests |
| --max-log-len | 최대 로그 길이 | None | --max-log-len 100 |
고급 설정
| 옵션 | 설명 | 기본값 | 예시 |
| --device | 실행 디바이스 | auto | --device cuda |
| --ray-workers-use-nsight | Ray 워커에서 Nsight 사용 | False | --ray-workers-use-nsight |
| --num-scheduler-steps | 스케줄러 단계 수 | 1 | --num-scheduler-steps 2 |
| --multi-step-stream-outputs | 멀티스텝 스트림 출력 | False | --multi-step-stream-outputs |
| --enable-prefix-caching | 프리픽스 캐싱 활성화 | False | --enable-prefix-caching |
| --disable-sliding-window | 슬라이딩 윈도우 비활성화 | False | --disable-sliding-window |
| --use-v2-block-manager | 블록 매니저 v2 사용 | True | --use-v2-block-manager |
| --enable-chunked-prefill | 청크 프리필 활성화 | False | --enable-chunked-prefill |
DGX Spark 특화 옵션
| 옵션 | 설명 | 기본값 | 예시 |
| --attention-config.backend | 어텐션 백엔드 | None | --attention-config.backend flashinfer |
| --tool-call-parser | 툴 호출 파서 | None | --tool-call-parser glm47 |
| --reasoning-parser | 추론 파서 | None | --reasoning-parser glm45 |
| --enable-auto-tool-choice | 자동 툴 선택 활성화 | False | --enable-auto-tool-choice |
API
OpenAI 형식을 호환한다.
Header
| 헤더 | 형식 | 설명 | 예시 |
| Authorization | Bearer 토큰 | API 키 인증 (--api-key 사용 시) | Authorization: Bearer your-api-key |
| Content-Type | MIME 타입 | 요청 본문 타입 | Content-Type: application/json |
Endpoint
생성
| 엔드포인트 | HTTP Method | 기능 | 설명 |
| /v1/chat/completions | POST | 채팅 완성 | 대화형 텍스트 생성, 멀티턴 채팅 지원 |
| /v1/completions | POST | 텍스트 완성 | 단일 프롬프트 기반 텍스트 생성 |
| /v1/models | GET | 모델 목록 | 서버에서 사용 가능한 모델 목록 조회 |
| /v1/embeddings | POST | 임베딩 생성 | 텍스트 임베딩 벡터 생 |
vLLM
| 엔드포인트 | HTTP Method | 기능 | 설명 |
| /tokenize | POST | 토큰화 | 텍스트를 토큰 ID로 변환 |
| /detokenize | POST | 디토큰화 | 토큰 ID를 텍스트로 변환 |
| /inference/v1/generate | POST | 직접 생성 | vLLM 네이티브 생성 API |
| /pooling | POST | 풀링 연산 | 풀링 모델 특징 추출 |
기타 자세한 옵션은 vLLM 서버 설치 후 `/docs` 엔드포인트로 API 목록들을 확인할 수 있다.
docker-compose.yml
공통 옵션들은 `&(anchor)` 와 `*(alias)`를 사용하여 수정 시 한 곳만 수정해도 전부 적용되게 해 놓았다.
주의: 장비, 모델, 환경에 따라 추가적인 옵션설정이 필요할 수 있음.
version: '3.8'
x-common-config: &common-config
image: vllm-node
privileged: true
stdin_open: true
tty: true
network_mode: host
ipc: host
volumes:
- ~/.cache/huggingface:/root/.cache/huggingface
x-common-deploy: &common-deploy
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
services:
vllm-qwen25-7b:
container_name: qwen25-corder7b
<<: *common-config
command: >
bash -c -i "vllm serve
Qwen/Qwen2.5-Coder-7B-Instruct-AWQ
--port 8005 --host 0.0.0.0
--gpu-memory-utilization 0.15
--max-num-seqs 8
--tensor-parallel-size 1
--kv-cache-dtype auto
--enable-auto-tool-choice
--tool-call-parser hermes
--trust-remote-code
--max-model-len 32768
--load-format fastsafetensors"
deploy:
<<: *common-deploy
vllm-qwen25-32b:
container_name: qwen25-corder32b
<<: *common-config
command: >
bash -c -i "vllm serve
Qwen/Qwen2.5-Coder-32B-Instruct-AWQ
--port 8007 --host 0.0.0.0
--gpu-memory-utilization 0.45
--kv-cache-dtype auto
--trust-remote-code
--max-model-len 32768
--enable-auto-tool-choice
--tool-call-parser hermes
--max-num-seqs 4
--tensor-parallel-size 1
--load-format fastsafetensors"
deploy:
<<: *common-deploy
vllm-qwen25-14b:
container_name: qwen25-corder14b
<<: *common-config
command: >
bash -c -i "vllm serve
Qwen/Qwen2.5-Coder-14B-Instruct-AWQ
--port 8006 --host 0.0.0.0
--gpu-memory-utilization 0.25
--kv-cache-dtype auto
--trust-remote-code
--max-model-len 16384
--max-num-seqs 6
--enable-auto-tool-choice
--tool-call-parser hermes
--tensor-parallel-size 1
--load-format fastsafetensors"
deploy:
<<: *common-deploy
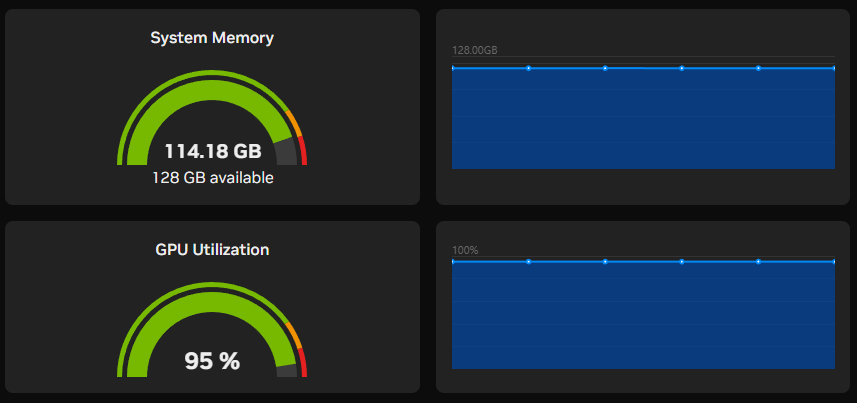
DGX Spark 장비에서는 위 옵션으로 전부 가동하였을 때 무사히 동작하였고,
3개 전부 가동 시 메모리 공간이 아래 사진과 같이 점유 중인 것을 확인할 수 있다.
가동만 함

질문 응답 중
서버 정상 Ready시 Log
qwen25-corder14b | (APIServer pid=1) INFO: Started server process [1]
qwen25-corder14b | (APIServer pid=1) INFO: Waiting for application startup.
qwen25-corder14b | (APIServer pid=1) INFO: Application startup complete.서버 가동실패 Log
RuntimeError: Engine core initialization failed. See root cause above. Failed core proc(s): {}위와 같은 내용이 나올 경우 `gpu-memory-utilization` 옵션을 적절히 수정한다.
위에도 작성했다시피 해당 옵션은 "vRAM의 몇 %를 사용할 것이냐"와 같은 옵션이라 다른 곳에서 vRAM을 사용하는 앱이 있다면 종료해야 하며 여러 vLLM 서버를 올릴 경우 적절히 수정해야 한다.(너무 낮으면 답변 품질이 매우 나쁘다)
적절히 수정해도 같은 오류가 난다? -> 재부팅 후 정상적으로 켜질 때까지 계속 `compose up` 시켜준다.
'Local AI' 카테고리의 다른 글
| [TTS] GPT-SoVITS 설치부터 API 활용까지 (0) | 2026.02.04 |
|---|---|
| [AI TOOL] Comfy-UI 설치부터 API 활용까지 (0) | 2026.02.03 |